
További Tech cikkek
-
 Az Instagram ezentúl korlátozza a politikai tartalmakat
Az Instagram ezentúl korlátozza a politikai tartalmakat - Japán szigorítana a mesterséges intelligencia fejlesztésén
- Elképesztő változáson esik át a Waze
- Fél évig akár féláron is használhatják a vezetékes internetet a Digi előfizetői
- Aggódik az Apple az iPhone miatt, biztonsági kockázatokat rejthet egy uniós szabályozás
Az utóbbi években az internetes tartalmak bővülése és a fájlcserélők terjedése miatt a tudományos életben és a felsőoktatásban is egyre gyakrabban találkozhatunk szó szerint lemásolt tartalommal. Ennek kiszűrésére számos megoldás született már, itthon a Magyar Tudományos Akadémia Számítástechnikai és Automatizálási Kutatóintézete által fejlesztett KOPI Plágiumkereső a legismertebb.
Az ingyenes szolgáltatás adatbázisa a Wikipedia összes magyar, angol, német és francia szócikkén keres. A program új szolgáltatása felismeri a szó szerinti magyarra fordítást is. Az előfeldolgozás érdekessége, hogy önkéntes felajánláson alapuló Desktop Grid rendszeren működik, vagyis beszállhat saját processzoridővel.
Egy szerver már nem elég
Amikor 2002-ben az MTA SZTAKI Elosztott Rendszerek Osztálya elkezdte a KOPI fejlesztését, éppen csak megkezdte működését az angol Wikipédia, most pedig csaknem 3,8 millió szócikke van. Ebből is látszik, hogy a plágiumkeresés megfelelő működésének biztosítása igen hosszú és számításigényes feladat, amely egyetlen számítógépen akár hónapokig is eltartana. A SZTAKI Desktop Grid rendszere viszont ezt napok alatt képes elvégezni ezt a feladatot.
Valaki lebukott...
Ez a közösségi erőforrás-felajánláson alapuló megoldás lehetővé teszi, hogy bárki hozájáruljon személyi számítógépének szabad kapacitásával a KOPI frissítéséhez. Jelenleg a munkát több mint 34 ezer felhasználó segíti, de a portál alkotói bíznak abban, hogy újság- és könyvkiadók, bloggerek és a média egyéb szereplői is felismerik a nemzetgazdaság és a társadalom érdekeit, ezért szabad kapacitásukkal beszállnak a keresésbe – mondta el az Indexnek Pintér Dániel Gergő, az MTA SZTAKI sajtóreferense. Pintér szerint ahogy számítógépeink egyre gyorsabbak, fejlettebbek lesznek, az átlagfelhasználó csupán kapacitásuk körülbelül 20 százalékát használja ki a böngészést, levelezést, és közösségi oldalakat felölelő napi rutin során.
Ctrl+C és a Ctrl+V a szövegtörzs
Most, hogy nemzetközi szinten is egyre több politikus és egyetemi tanár doktori disszertációjáról derül ki, hogy a szövegtörzsbe fektetett idejük jelentős része a Ctrl+C és a Ctrl+V gombok intenzív, egymás utáni lenyomásából állt, nő a plágiumadászok és jogvédők száma is.
Az idézőjelek elhagyása vagy a forrásmegjelölés mellőzése sokakat bőszít: Debora Weber-Wulff berlini professzor például WiseWoman becenéven tájékoztatja olvasóit a szellemi tulajdonnal kapcsolatos visszajelzésekről. 2010-ben 48 plágiumkeresőt tesztelt, és arra jutott, hogy az alkalmazások gyenge pontja az, hogy képtelenek kiszűrni a fordításokat. Pataki Máté, a SZTAKI tudományos munkatársa szerint ebben rejlik a KOPI újdonsága is: „A DSD által fejlesztett algoritmus képes az angol Wikipédiából átvett és magyarra fordított anyagokat is megtalálni: ezzel ez a világ első, fordítást is felismerő plágium-keresője."

Pontos találatok
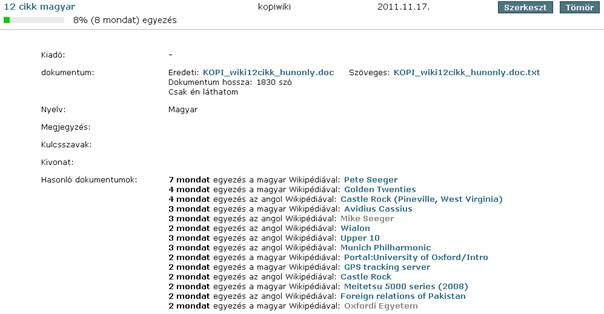
A KOPI megtalálja a magyar Wikipédiából átvett anyagokat is, akkor is, ha azt nem szó szerint szerepelnek a műben. A felhasználók által feltöltött közel harmincezer mű közötti egyezést is kijelzi a portál, ezután pedig megismerteti a látogatókat az ide vonatkozó jogszabályi háttérrel és rendeletekkel is. Ráadásul beépíthető külső rendszerekbe is, így megvédhet akár olyan digitális gyűjteményeket is, melyekhez csak regisztrált felhasználók férhetnek hozzá. A SZTAKI jövőbeli tervei között szerepel digitális könyvtárak védelme, illetve magyar nyelvű, interneten található tartalmak begyűjtése.
Kövesse az Indexet Facebookon is!
Követem!
