
Kövesse az Indexet Facebookon is!
Követem!További Net cikkek
Hiába tűnnek fel újabbnál újabb keresők, gyakran előfordul, hogy egyáltalán nem, esetleg nem azt találjuk, vagy nehézkesen bukkanunk rá arra, ami után kutakodunk. Ugyan mind gyakrabban hallunk szemantikus technológiákról, de a jelentésalapú keresés és ismeretfeltárás még gyerekcipőben jár.
Az Illinois Egyetem több tanszékén gőzerővel folynak az ilyen jellegű kutatások. Nemcsak a web-böngészést akarják hatékonyabbá tenni, hanem szerteágazó területeken óhajtanak minél használhatóbb eredményeket elérni, keresési módszereket és programokat kidolgozni: irodalomtudományban, új gyógyászati eljárások genetikai adatbázisokból nyert információk alapján történő kikísérletezésében, terrorista tevékenység azonosításában, és így tovább.


Mire jók a kulcsszavak?
A Számítástudományi Központban dolgozó Anhai Doan nemrég akart házat vásárolni - pontosan meghatározott környéken, szobaszámmal (nappali, hálószobák, stb.). Leendő otthona méretéről szintén konkrét elképzelései voltak. A fizetés módjáról, a kölcsönlehetőségekről is a lehető legtöbbet szerette volna megtudni. Online kutakodása hiábavalónak bizonyult: sehonnan nem kapott összes kívánságára kiterjedő, homogén, állandóan frissülő listát. Pedig valamennyi létezik elektronikus formában, csakhogy hiába próbálkozott a keresőkkel (Google, Yahoo, stb.), nem találta meg, amire vágyott.
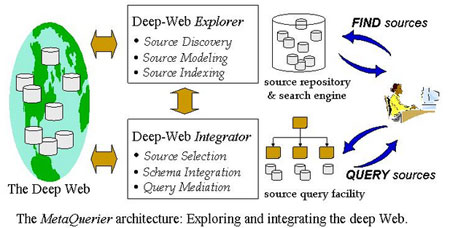
"Nincs lehetőség arra, hogy a kulcsszavas módszerrel ilyen esetekben eredményt érjünk el" - jelentette ki Doan.
Kollégáival a mindannyiunk által ismert és megszokott, manapság a Google megtestesítette keresésnek a tényleges adatbányászattal történő fokozatos helyettesítését óhajtják kivitelezni, s e célnak megfelelő programokat fejleszteni. Céljuk, hogy a mind terebélyesebb digitális matériából a legváratlanabb alkalmakkor, a legváratlanabb helyeken jussunk hozzá hasznos mintákhoz, tényleges ismerethez.
Magánszféra, közszféra
Az eredmények minden bizonnyal komoly érdeklődésre tartanak majd számot. Ugyanakkor, mint az összes hasonló jellegű projekt kapcsán, ezúttal is felmerül a magánélet, a privacy kérdése: meddig nyilvánosak az adatok, mikortól számít közzétételük a személyes szféra megsértésének? Az utóbbi idők néhány botránya - például hitelkártya-gyártókkal szemben elkövetett számítógépes lopások -, valamint a könyvtári bejegyzéseknek, a hálózati kommunikációnak és a telefonhívásoknak a terrorizmus elleni harc jegyében történő permanens megfigyelése egyre gyakrabban vetik fel az információval való visszaélés kérdését.
A fejlesztőknek különösen az "adatbázisokból történő ismeretfeltárást" (knowledge discovery in databases) célzó projekteknél - már amennyire lehetséges - figyelembe kell venniük mindezt. Akárcsak azt a tényt, hogy a feldolgozandó matéria javarésze eleve digitális formában keletkezett (born digital): soha nem látott, és nem is fog látni papírt.
Jiawei Han, az egyetem Adatbányász Kutatócsoportjának professzora szerint a számítási kapacitások exponenciális növekedése teljesen új adatfelhasználást tesz lehetővé: az információra való következtetéshez nem kell az adatözönből statisztikai módszerekkel mintákat gyűjtögetni, hanem immáron teljes adatsoroknak (például az e-bay-en kivitelezett összes vásárlásnak, az emberi test génállományának, stb.) is nekiveselkedhetünk.
Java vagy Java?
Az eljárást tesztprojektben ellenőrzik: a William Gibson magyarul Trendvadászként megjelent Pattern Recognition-jének (Mintafelismerés) egyik szereplőjéről elnevezett NORA (No One Remembers Acronyms, "senki nem emlékezik betűszavakra") számítógépe izgalmas minták után nyomoz; például többezer szó, szókapcsolat alapján előre jelezte, Emily Dickinson mely verseit tartják a témára szakosodott irodalmárok erotikusnak.
Az egyetem más projektjeiben az ember és néhány emlős génállományában a rák és más betegségek elleni küzdelemben felhasználandó közös mintákat (Evolution Highway), vagy éppen a méhekre vonatkozó, de egyéb állatok és a Homo sapiens elemzésénél is fontos adatokat (BeeSpace) keresnek...
A hatékony munkához azonban másként kell a képeket, videókat és egyéb nem-szöveges anyagokat tartalmazó adatbázisokban keresni, katalogizálni - állítja Thomas Huang professzor. Konklúziója: a világhálón talált adatoknak relevánsabbnak kell lenniük, könnyebben és gyorsabban hozzájuk kell férnünk. Ha nem, akkor elveszünk a végtelenben.
Az említett relevancia csak akkor valósulhat meg, ha számítógépeink a mainál nagyságrendekkel jobban kezelik a jelentés kérdését. Ha például meg tudják különböztetni Java szigetét a Java programnyelvtől.
Kövesse az Indexet Facebookon is!
Követem!
