

Még él, és keresi a szexet a legelső webkereső

Kövesse az Indexet Facebookon is!
Követem!További Ma Is Tanultam Valamit cikkek
Az internetezők 90 százaléka a legtermészetesebb mozdulattal a Google-t nyitja meg a gépén, ha keresni szeretne valamit az interneten (az egyeduralkodó Google mellett labdába rúg még pár százalékkal a Bing, a kínai webet uraló Baidu és az egykori number one Yahoo!). A netes keresés annyira eggyé vált a Google nevével, hogy igeként át is szivárgott a köznyelvbe – aki nem hiszi, guglizzon rá.
Nem volt ez persze mindig így, a Google 1998-as indulása előtt természetesen más keresőket használtak az internetezők: ha a magyar netre gondolunk, eszünkbe juthat a szép emlékű Heureka vagy a vicces nevű Altavizsla, a hazai webtörténelem két legnépszerűbb keresője. Külföldi keresők közül a WebCrawler, a Lycos, az Altavista (a magyar kereső nevét ihlető amerikai nagytestvér) biztos hogy felrémlik a legalább húsz-harmic éve netező olvasóknak. Az igazán veterán webezőknek pedig ismerősen csenghet az AliWeb, az első webes keresőoldal neve is. És bár az internet végül nem bizonyult annak a világméretű könyvtárnak, aminek a kezdetek kezdetén megálmodták, amiben minden tudás és tartalom megőrződik az idők végezetéig, azért szerencsére vannak olyan szegletei, amik megőriztek valamit a világháló kezdeteiből – ilyen szeglet a www.aliweb.com, ahol a mai napig látogatható a legendás kereső.
Az AliWeb (ALIWEB) több mint 24 évvel ezelőtt indult. A név mozaikszó, az "Archie Like Indexing for the Web" kifejezésből adódik, és arra utal, hogy a kereső működése a weboldalak indexelésén (katalogizálásán) alapul, ahogy elődje, Archie – a montreaéli McGill Egyetemen 1990-ben beüzemelt, WWW (World Wide Web) előtti legelső őskereső –, a korabeli egyetemi számítógépes hálózatokra kötött FTP szerverek könyvtárait, fájljait listázta.
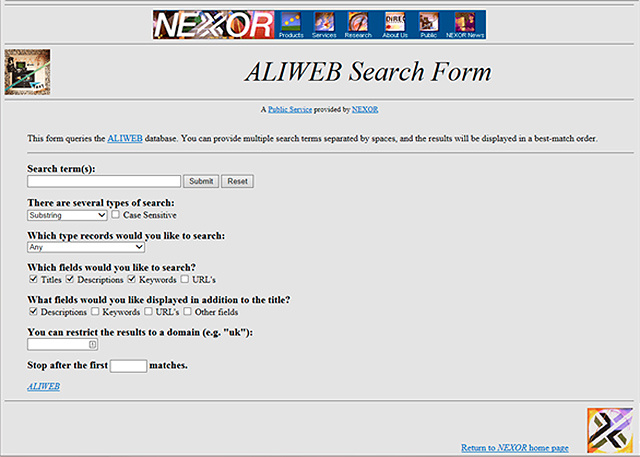
Így nézett ki a kezdetek kezdetén az első webes kereső
Martijn Koster, az AliWeb atyja, a brit Nexor kiberkommunikációs cég egyik fejlesztője, 1993 novemberében adott hírt egy kollégáinak küldött emailben az AliWebről. Mint írta, a céges levelezésben (akkor még hírcsoportnak hívták a levlistákat) hetente sóhajtott fel valaki, hogy milyen jó lenne egy Archie-hoz hasonló kereső a weben is, bár a kézzel frissítgetett fájlkatalógusok helyett egy automatikus indexelő szolgáltatás jobb lenne. Koster azt írta, hogy az AliWeb automata "megosztott" indexelésre tesz kísérletet: ha egy webszerver egy lokálisan tárolt fájlban leírja a rajta tárolt tartalmakat, akkor azt a kereső bizonyos időközönként – naponta – automatikusan lekéri, tárolja és feldolgozza, és az így létrehozott indexadatbázisban tudnak keresni a weben érkező felhasználók. Koster arra biztatta a webszerverek üzemeltetőit, hogy csatlakozzanak a nem túl költséges kísérlethez, ami rövid időn belül hasznos eszközzé nőheti ki magát.
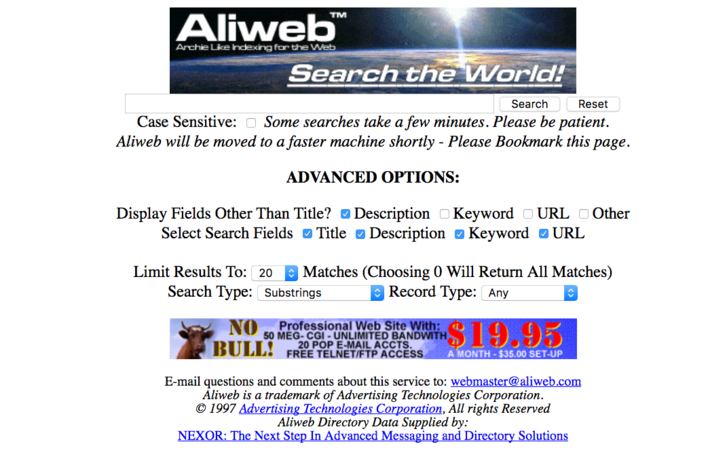
Az AliWeb 1997-ben...
Az első webes keresőt 1994 májusában mutatta be Koster Genfben, a CERN-ben tartott Első Nemzetközi Világháló Konferencián (First International Conference on the World-Wide Web), jó pár hónappal megelőzve a WebCrawler nevű, metaadatokkal dolgozó vetélytársat. Az AliWeb működése viszonylag egyszerű volt: a katalógusba jelentkező felhasználók megadták a felvenni kívánt weboldal indexfájljainak elérését (site.idx néven, a publikus html struktúra fölső szintjén, pl: http://www.mywebpage.com/site.idx), ezzel a keresőmotor tárolni tudta a weboldal elérését, hozzáfűzve a felhasználók által megadott leírást és kulcsszavakat. Így a weboldalak fenntartói (a webmesterek) gyakorlatilag szabad kezet kaptak, hogy meghatározzák milyen kereső-kifejezések beírásával juthatnak el a felhasználók az oldalaikra.
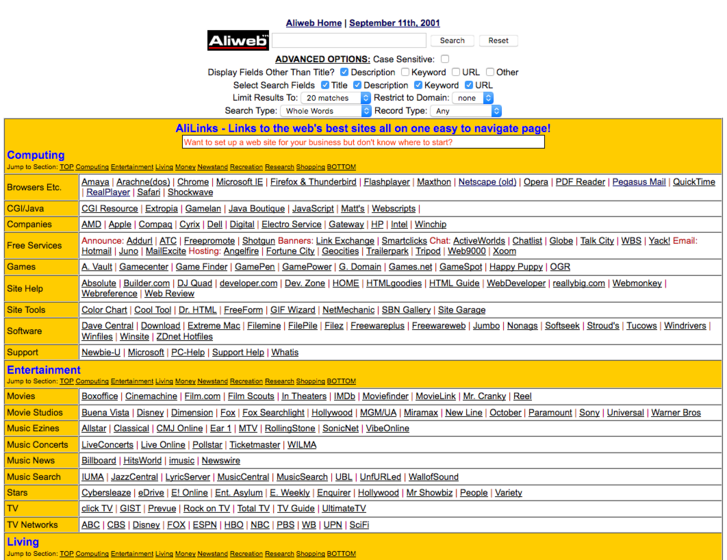
...és 2018-ban
Az AliWeb végül nem vált a világháló meghatározó keresőjévé, leginkább azért, mert nem gyarapodott kellő mértékben az általa indexált oldalak listája, kevés webmester vette a fáradságot, hogy felvetesse az általa üzemben tartott oldal adatait az aliwebes katalógusba. Ennek ellenére az AliWeb az internet egyik nagy túlélője: a www.aliweb.com-on jószerével úgy láthatjuk az oldalt, ahogy a kétezres évek elején belefagyott az időbe. A nyitólapon, a keresőmező alatti rikító sárga lepedőn nyolc fő kategóriába (Számítástechnika, Szórakozás, Életmód, Pénz, Hírek, Pihenés, Kutatás, Vásárlás) rendezve olyan weboldalak neveit böngészhetjük, amikre már szinte senki nem emlékszik alkotójukon kívül, a kereső használatával pedig egészen obskúrus internetes kövületekre, még létező ősweboldalakra lehet kis szerencsével bukkanni – kész időutazás az 1.0-ás web kezdeteihez. És hát alább a bizonyíték, hogy a netezők már a kezdetek-kezdetén is keresték a szexet a weben, egy friss keresés is előhoz rég letűnt XXX oldalakat, jpeg-baby gyűjtemények címeit:

Mi másra is kereshetnénk? Sajnos a keresés találatai már elvesztek az időben, mint könnycseppek az esőben.
Érdemes még rákattintani a legfölül lévő "September 11th, 2001" linkre is, ami a 17 éve történt New York-i terrortámadás után készült oldalra vezet, és a World Trade Center tornyainak leomlása utáni nehéz időszakban próbált segítséget nyújtani az információkereséhez. Hátborzongató kordokumentum a maga módján:

Nyitókép: Bill O'Leary/The Washington Post / Getty Images Hungary


Kövesse az Indexet Facebookon is!
Követem!

Rovataink a Facebookon