


További Tech cikkek
Az utóbbi években az internetes tartalmak bővülése és a fájlcserélők terjedése miatt a tudományos életben és a felsőoktatásban is egyre gyakrabban találkozhatunk szó szerint lemásolt tartalommal. Ennek kiszűrésére számos megoldás született már, itthon a Magyar Tudományos Akadémia Számítástechnikai és Automatizálási Kutatóintézete által fejlesztett KOPI Plágiumkereső a legismertebb.
Az ingyenes szolgáltatás adatbázisa a Wikipedia összes magyar, angol, német és francia szócikkén keres. A program új szolgáltatása felismeri a szó szerinti magyarra fordítást is. Az előfeldolgozás érdekessége, hogy önkéntes felajánláson alapuló Desktop Grid rendszeren működik, vagyis beszállhat saját processzoridővel.
Egy szerver már nem elég
Amikor 2002-ben az MTA SZTAKI Elosztott Rendszerek Osztálya elkezdte a KOPI fejlesztését, éppen csak megkezdte működését az angol Wikipédia, most pedig csaknem 3,8 millió szócikke van. Ebből is látszik, hogy a plágiumkeresés megfelelő működésének biztosítása igen hosszú és számításigényes feladat, amely egyetlen számítógépen akár hónapokig is eltartana. A SZTAKI Desktop Grid rendszere viszont ezt napok alatt képes elvégezni ezt a feladatot.
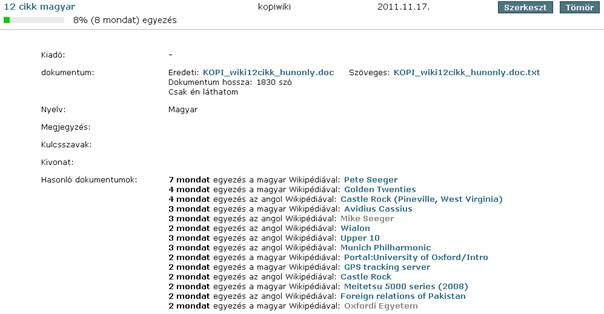
Valaki lebukott...
Ez a közösségi erőforrás-felajánláson alapuló megoldás lehetővé teszi, hogy bárki hozájáruljon személyi számítógépének szabad kapacitásával a KOPI frissítéséhez. Jelenleg a munkát több mint 34 ezer felhasználó segíti, de a portál alkotói bíznak abban, hogy újság- és könyvkiadók, bloggerek és a média egyéb szereplői is felismerik a nemzetgazdaság és a társadalom érdekeit, ezért szabad kapacitásukkal beszállnak a keresésbe – mondta el az Indexnek Pintér Dániel Gergő, az MTA SZTAKI sajtóreferense. Pintér szerint ahogy számítógépeink egyre gyorsabbak, fejlettebbek lesznek, az átlagfelhasználó csupán kapacitásuk körülbelül 20 százalékát használja ki a böngészést, levelezést, és közösségi oldalakat felölelő napi rutin során.
Ctrl+C és a Ctrl+V a szövegtörzs
Most, hogy nemzetközi szinten is egyre több politikus és egyetemi tanár doktori disszertációjáról derül ki, hogy a szövegtörzsbe fektetett idejük jelentős része a Ctrl+C és a Ctrl+V gombok intenzív, egymás utáni lenyomásából állt, nő a plágiumadászok és jogvédők száma is.
Az idézőjelek elhagyása vagy a forrásmegjelölés mellőzése sokakat bőszít: Debora Weber-Wulff berlini professzor például WiseWoman becenéven tájékoztatja olvasóit a szellemi tulajdonnal kapcsolatos visszajelzésekről. 2010-ben 48 plágiumkeresőt tesztelt, és arra jutott, hogy az alkalmazások gyenge pontja az, hogy képtelenek kiszűrni a fordításokat. Pataki Máté, a SZTAKI tudományos munkatársa szerint ebben rejlik a KOPI újdonsága is: „A DSD által fejlesztett algoritmus képes az angol Wikipédiából átvett és magyarra fordított anyagokat is megtalálni: ezzel ez a világ első, fordítást is felismerő plágium-keresője."

Pontos találatok
A KOPI megtalálja a magyar Wikipédiából átvett anyagokat is, akkor is, ha azt nem szó szerint szerepelnek a műben. A felhasználók által feltöltött közel harmincezer mű közötti egyezést is kijelzi a portál, ezután pedig megismerteti a látogatókat az ide vonatkozó jogszabályi háttérrel és rendeletekkel is. Ráadásul beépíthető külső rendszerekbe is, így megvédhet akár olyan digitális gyűjteményeket is, melyekhez csak regisztrált felhasználók férhetnek hozzá. A SZTAKI jövőbeli tervei között szerepel digitális könyvtárak védelme, illetve magyar nyelvű, interneten található tartalmak begyűjtése.
Kövesse az Indexet Facebookon is!
Követem!Az oldalról ajánljuk
- Külföld

Újabb csúcstalálkozót tart a „tettre készek koalíciója” Párizsban
Emmanuel Macron jelentette be a hírt.
március 21., 09:26
- Belföld

Rá sem ismerünk a Kárpát-medence időjárására, nem a fűtésre költünk majd legtöbbet
Szegedi tudósok kutatócsoportja vizsgálja, miért kezdett el a város klímája Rómáéhoz hasonlítani.
március 21., 09:06
- Atlétika

Áttörés az M4 Sporton: világszerte minden magyar nappalijába beköltözik a nancsingi fedett pályás vb
Az internet tényleg leküzdi az országhatárokat.
március 21., 09:20
- Gazdaság

Újabb bank merített hatalmasat a húsosfazékból
Kiemelkedő, sikeres, milliárdokban gazdag 2024-et tudhat maga mögött az MBH Bank.
március 21., 09:29
- Külföld

Csehország határellenőrzést vezet be a Magyarországon is terjedő halálos kór miatt
A cseh rendőrség megelőző intézkedéseket jelentett be.
március 21., 08:51
- Gazdaság

Ingatlanvásárlás 3 százalékos kamattal? Lehetséges, de nem mindenkinek
Van azonban buktató, ami súlyos milliókba fájhat.
március 21., 08:02
- Külföld

Donald Trump aláírta a rendeletet az oktatási minisztérium megszüntetéséről
Ezzel beváltotta egyik kampányígéretét.
március 21., 08:33
- Külföld

Olyan mértékű büntetést szabtak ki a Greenpeace-re, amely csődbe viheti a szervezetet
Zaklatás, rágalmazás és birtokháborítás miatt perelte be őket egy olajcég.
március 21., 09:10
- Futball

Az utolsó másodpercekben döntött Vinícius Júnior, kulcsfontosságú meccsen nyertek a brazilok
Ezzel négy pontra közelítették meg a listavezető argentinokat.
március 21., 10:04
- Belföld

VSquare: Orbán Viktor utasította a titkosszolgálatot a külföldről támogatott civilek és újságírók listázására
Kérdéses, mit kezd a kormány a jelentéssel.
március 21., 07:23
- Kultúr

Ez a doboz meghatározta a rendszerváltás előtti időszakot, az állam játékszerként használta
Azt remélik, nem tér vissza.
március 21., 05:55
- Cinematrix

A nőnek csak kussolni volt szabad – film, amely lenyomta a Barbie-t és az Oppenheimert is
A verés állandó, a nő cselédnek sem jó.
március 21., 09:52
- Külföld

A náci propagandaminiszterhez hasonlította a leendő német kancellárt a korábbi orosz elnök
Kemény vádat fogalmazott meg Dmitrij Medvegyev.
március 21., 07:34
- Belföld

Orbán Viktor: A külföldiek értsék meg, hogy a magyarokat nem lehet kifosztani
A kormányfő ezúttal is Brüsszelből jelentkezett.
március 21., 07:44
- Reklám

Ez a filmecske két perc alatt olyat mutat, amire évtizedek múlva is emlékezünk
Mindenkiről szól.
március 21., 05:54
- Külföld

Bécsben is tüntettek a magyar Pride betiltása ellen
Több százan voltak jelen az eseményen.
március 21., 09:54
- Belföld

Az a baj, hogy a vásárlók nem értik az áruházi kínálatot – vizsgálódik a GVH a teljes kiőrlésű termékek körül
Minden tizedik magyarnak fontos lenne, hogy a boltok ne csaljanak.
március 21., 05:54
- Belföld

Gulyás Gergely Magyar Péterről: Bolondokkal lehet barátkozni, árulókkal nem szabad
A miniszter egy interjúban beszélt a Tisza Párt elnöke és közötte lévő kapcsolatról.
március 21., 06:05
- FOMO

A filmvászon kaméleonja, akinek a lábai előtt hever a szakma
67 éves lett Gary Oldman.
március 21., 05:59
- Külföld

A lengyel belügy arra kéri az embereket, hogy három napra elegendő élelmiszerrel készüljenek fel a válsághelyzetekre
Új védelmi stratégiát dolgozott ki a kormány.
március 21., 06:52
- FOMO

Alig két év házasság után újra válik Sia
Az énekesnő második házassága is tönkrement.
március 21., 06:10
- Külföld

Miért engedi az Egyesült Államok az oroszok területi terjeszkedését?
A Kreml remek lehetőséget lát, hogy kedvező alkut kössön.
március 21., 06:55
- Külföld

Tűz ütött ki Európa legnagyobb repülőterénél, egész napra bezártak
Az incidensben több mint ezer járat érintett.
március 21., 06:32
- Belföld

Éjszakai fagyok és szikrázó napsütés, nagy hőingásra számíthatunk
A legmagasabb nappali hőmérséklet döntően 13 és 18 fok között alakul.
március 21., 06:05
- Külföld

Donald Trump ellenségeskedése miatt felmerült, hogy Kanada az Európai Unióhoz csatlakozna
Egyáltalán lehetséges ez?
március 21., 06:55
- Belföld

Három férfi erőszakolt meg egy nőt egy 11 éves gyerek szeme láttára
Az elkövetőket letartóztatták.
március 21., 09:38
- Belföld
Mintegy félmilliós tartozása miatt vertek agyon egy nyugdíjas taxist Pestszentimrén
A feltételezett gyilkost órákon belül elfogták.
március 21., 05:59
- Külföld
2024-ben mintegy négyezren választották az eutanáziát Belgiumban
Az igénylők száma 16,6 százalékkal növekedett egy év alatt.
március 21., 07:13

