


A gép újabb nagy győzelme, de az ember még mindig intelligensebb

Kövesse az Indexet Facebookon is!
Követem!További Tech cikkek
Jó év vár a mesterséges intelligencia (MI) kutatóira. 2016 rögtön egy nagy bejelentéssel indult: az AlphaGo nevű programnak a világon először sikerült elverni egy profi emberi játékost a gó nevű táblajátékban. Elmagyarázzuk, hogyan csinálta, és miért örül ellek mindenki.
Játszani is engedd szép, komoly gépedet
A különféle játékok már jó ideje az MI-kutatás kedvelt terepének számítanak, mert világos cél és szabályok jellemzik őket, kontrollált tesztkörnyezetet biztosítanak a kísérleteknek, jól mérhetőek, és nem utolsó sorban kifelé is látványos eredmények születhetnek.
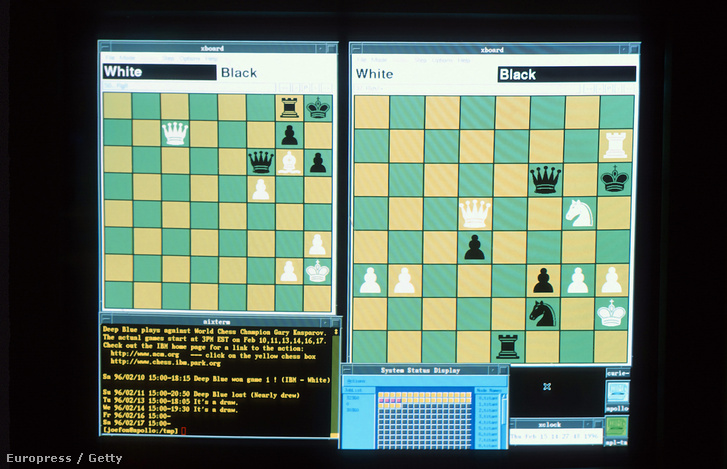
Az ember és a gép küzdelmének klasszikus terepe a sakk, ebben már fél évszázada megszülettek az első próbálkozások az MI-vel. A leghíresebb párbaj viszont vitathatatlanul az IBM szuperszámítógépe, a Deep Blue és Garri Kaszparov sakkvilágbajnok között zajlott, és 1997-ben a gép történelmi győzelmével zárult. Szintén nagy szenzációnak számított, amikor az IBM egy másik gépe, az azóta is az MI-kutatás egyik ikonjának számító Watson 2011-ben megnyerte a Jeopardy! nevű amerikai tévés vetélkedőt az emberi bajnokokkal szemben.

Watson 2011-es győzelme a Jeopardy! játékban.
Fotó: IBM
A gót viszont még az utóbbi években is meghódíthatatlan csúcsnak tartották az MI-kutatók. Eddig a legtovább a francia Rémi Coulom rendszere, a Crazy Stone jutott, amely többször is nyert már ember ellen – csakhogy ehhez mindig jelentős előnyből kellett kezdenie a játékot. Még idén január elején is neves kutatók kérdőjelezték meg, hogy mostanában sikerülhet egyenlő küzdelemben legyőzni egy emberi gómestert, de tavaly olyan jóslat is elhangzott, hogy még legalább egy évtizedig biztosan nincs veszélyben az emberi intelligenciának ez a bástyája.
Nem így gondolta viszont a Google.
Pontosabban a DeepMind nevű cég, amelyet még 2014-ben vásárolt fel a Google, és a modern MI-kutatás egyik éllovasának számít. Ezért nem sajnálta a Google a 400 millió dollárt (115 milliárd forintot) arra, hogy elhappolja a Facebook elől. Eddig bejött az üzlet, a DeepMind már eddig is látványos eredményeket produkált, és az AlphaGót is ők fejlesztették.
Machina ludens
Maga a történelmi meccs valójában már októberben lezajlott. A DeepMind londoni irodájában eresztették össze az AlphaGo nevű rendszert a Fan Hui nevű emberrel, aki kínai származású francia gójátékos, és a legutóbbi három Európabajnokság nyertese. Az összecsapást egy hivatásos gó-döntőbíró és a Nature folyóirat egy szerkesztője is felügyelte, és a mesterséges intelligencia zsinórban öt játszmában múlta felül az igazit. (A Nature szerkesztője azért volt ott, mert a kutatók náluk publikálták az algoritmus leírását, ez jelent meg most januárban.)

Táncoló kínai robot a 2016-os CES-en Las Vegasban.
Fotó: AFP
De mi is egyáltalán az a gó? Egy több ezer éves, kínai eredetű játék. Az alapszabályok elég egyszerűek: két játékos felváltva pakol fekete és fehér köveket egy 19x19 vonalból álló pályára, a vonalak 361 metszéspontjára, azzal a céllal, hogy minél nagyobb területet szerezzenek egymás köveinek a bekerítésével. A játékot világszerte 60 millióan játsszák, de Magyarországnak is van saját gószövetsége, klubokkal, egyesületekkel és több száz nyilvántartott játékossal.
Bár első hallásra nem tűnik annyira vészesnek, a gó azért olyan őrülten nehéz terep, mert rengeteg variáció és lehetséges lépés képzelhető el, sokkal több, mint bármilyen másik játéknál, és még a legerősebb mai gépeknek sincs elég számítási kapacitása arra, hogy belátható idő alatt minden lépés összes kimenetelét kiszámolják.
Márpedig a Deep Blue pontosan ezt tette, amikor elverte Kaszparovot sakkban. Viszont amíg ott körönként átlagosan 35 lehetőség közül kellett kiválasztani a legjobbat, a gónál több variáció van, mint amit akkor kapnánk, ha az univerzum összes atomján egyszerre folyna egy-egy sakkjátszma. Ezt puszta számolgatással már nem lehet feldolgozni, vagy legalábbis beleöregednénk, mire vége lenne egyetlen menetnek. Ezért a legjobb játékosok se úgy feszülnek neki, mint az Esőember a kaszinóban, ennél a hozzáértők szerint sokkal intuitívabb játékról van szó.
A siker kulcsa a mélytanulásnak nevezett technológia.
Ennek a lényege, hogy a kutatók az idegrendszer biológiai modelljéről mintázott neurális hálózatokat építenek ki, amelyben a “neuronok” – a műveleteket végző egységek – közötti kapcsolatok változtatásával lehet a rendszert valamilyen feladatra hangolni. A rendszer központi eleme a mélytanulási algoritmus, amely a számára bemutatott mintákat rétegekre bontva elemzi, és ezek alapján önálló fejlődésre képes.
Deep Blue és Kaszparov sakk mérkőzése.
Fotó: Yvonne Hemsey
Az emberi intuíciót a gép nyilván nem tudja produkálni, de a kutatók azt várták ettől a módszertől, hogy a játék mintázatainak felismerésével sikerül áthidalni ezt a hiányt. A mélytanuláshoz is rengeteg adatot kell feldolgozni, de a gép ilyenkor nem nyers számítási erővel nyomul előre, hanem a sok-sok neki mutatott példán keresztül megtanulja elvégezni az adott feladatot. A fő különbség a fejlődés. Nem minden egyes lépésnél fog minden létező opciót lefuttatni, hanem idővel megtanulja, mivel érdemes próbálkozni:
- A kutatók először gójátékosok lépéseiből összeállítottak egy nagyjából 30 millió darabos gyűjteményt, ezzel etették az algoritmusukat, hogy az megtanulja önállóan játszani a játékot. Így elérték, hogy a gép 57 százalékos biztonsággal ki tudja találni az ellenfele következő lépését.
- De ez csak az első lépés volt, amellyel maximum annyit lehet elérni, hogy a gép pont olyan jó legyen, mint a mintául szolgáló emberi játékosok. Ezért a következő fázisban saját maga ellen játszatták a gépet: az emberi lépéseken edzett neurális hálón apró módosításokat végeztek, és ezeket a kicsit eltérő változatokat engedték egymásnak. Ezt hívják megerősítéses tanulásnak, amikor a gép értékeli, hogy egy-egy szituációban melyik lépéssel járt a legjobban, és ennek megfelelően finomhangolja magát. Pármillió játszma, és az AlphaGo magától profi gójátékossá fejlődött.
- Végül az így kapott eredményeket kombinálták korábbi technikákkal, hogy egy minden eddiginél profibb mesterséges gójátékost kapjanak. Lóerő azért ehhez is kell bőven. A mélytanuláshoz elsősorban grafikus csipekra van szükség, ebből a Fan Hui elleni meccshez használt hálózaton nagyjából 170 dolgozott egyszerre, plusz 1200 hagyományos processzor is besegített.
Góöröm
Demis Hassabis, a DeepMind vezetője szerint a siker azért nagy jelentőségű, mert az AlphaGo nem egyszerűen egy nagyon erős rendszer, amellyel gondosan összeállított szabályokat tanultattak meg, hogy egyetlen feladatot tudjon, de azt nagyon. Ehelyett általános gépi tanulással maga jön rá, saját maga által generált adatból, hogyan oldhatja meg a neki szegezett feladatot – vagyis jelen esetben azt, hogy mindenkit porrá alázzon góban.

Gó játék.
Fotó: Europress / Getty
Maga a mélytanulás nem új találmány, a modern MI-kutatás egyik központi területe. 2015-ben már a hétköznapjainkba is beszivárgott, hiszen olyan dolgokat tesz lehetővé a gépeknek, mint az élőbeszéd megértése, a képek tartalmának felismerése vagy éppen a valós idejű fordítás. Hassabis szerint viszont a mostani siker már az előszele annak a jövőnek, ahol a fizikai testtel rendelkező robotok képesek lesznek megtanulni fizikai feladatok elvégzését valódi fizikai környezetben. Az orvosi diagnosztikán és a tudományos munkán viszont már hamarabb is nagyot lendíthetnek az MI-kutatás legfrissebb eredményei.
Kapcsolódó

Mesterséges intelligenciát tett a zsebünkbe a Google
Ez teszi lehetővé, hogy most már magyarul is valós időben fordítson a mobilunk. Na meg a neurális hálózatok és a mélytanulási algoritmus.
Addig is AlphaGo gózik tovább, sőt a kutatók emelik is a tétet: március közepén Dél-Koreába szállítják, ahol Lee Sedollal fog játszani, aki a világ jelenlegi legjobbja.
A játékgépek lázadása?
A DeepMind legutóbbi nagy eredménye az volt, amikor tavaly februárban bejelentették, hogy egy algoritmusuk magától megtanult videojátékozni. Akkor a gép 49 régi Atari-játékkal birkózott meg önerőből. Sőt, annyiban az még nagyobb teljesítmény volt, mert az algoritmusnak semmit nem adtak meg előre, csak azt, hogy szerezzen sok pontot a játékokban, és minden információt menet közben kellett összeszednie a játékokról. Persze összehasonlíthatatlanul egyszerűbb feladatról van szó, mint egy profi gójátékos legyőzése.

Fotó: Nagy Attila
De ha a gépek már nemcsak nagyon intelligensek, hanem maguktól tanulnak is, akkor tényleg teljes gázzal száguldunk a robotapokalipszis felé? Bár komoly tudósok is óvatosságra intenek, azért ettől még messze vagyunk. A ma működő MI-rendszerektől mi sem áll távolabb, mint az öntudatosság, valójában inkább csak okosak, semmint a szó emberi értelmében intelligensek, nem értik, hogy mit csinálnak és miért, bármilyen ügyesen hajtják is végre a feladatot, amit kapnak.
Kapcsolódó

Kell-e félnünk a gépek lázadásától?
A mesterséges intelligenciától egyre többen féltik az emberiséget, legutóbb Stephen Hawking figyelmeztetett, hogy baj lesz. Még messze a szingularitás, de a Google már rákapcsolt. Okos dolog-e, hogy mindenünk okos?
Ráadásul az emberi intelligencia értelmezését se hagyja érintetlenül a mesterséges intelligencia kutatása. Ahogy egy gép elér egy újabb mérföldkövet, általában feljebb helyezzük a lécet. A logika is valahogy is vált emberi privilégiumból a számítógépek működésének alapjává, és bármilyen nagy eredmény, a gójátékos legyőzésével se a terminátor született még meg.
Kövesse az Indexet Facebookon is!
Követem!
