

Itt a Google új keresője, és mindenre megtalálja a választ a könyvtárban
További Tech cikkek
-
 Az Instagram ezentúl korlátozza a politikai tartalmakat
Az Instagram ezentúl korlátozza a politikai tartalmakat - Japán szigorítana a mesterséges intelligencia fejlesztésén
- Elképesztő változáson esik át a Waze
- Fél évig akár féláron is használhatják a vezetékes internetet a Digi előfizetői
- Aggódik az Apple az iPhone miatt, biztonsági kockázatokat rejthet egy uniós szabályozás
A Google a hétvégén elindította új keresési oldalát, a Talk to Books nevet viselő felületét, ahol bármilyen kérdésünkre egy pillanat alatt kihozza a választ a Google Books-on fent lévő könyvek virtuális átböngészésével.
Az oldal keresési adatbázisában egyelőre nagyságrendileg 100 ezer könyv szerepel, ezek alapján hozza ki a választ a kérdésünkre. Bár egy 100 ezres könyvtár igazán gazdag, a Gutenberg-galaxison belül csak néhány naprendszernyi kötetnek felel meg. Az 1440-es évek óta úgy 130 millió könyvet adtak ki idáig a világon (nagyjából ennyi cím létezik állítólag, a publikációk száma azonban évi 750 ezer új kiadású könyvvel bővül), sőt, a Google Books-ban is több, mint 25 millió könyv van már beszkennelve.
A Talk to Books-t a Google híres futurológusa, a szövegfelismeréssel, mesterséges intelligenciával foglalkozó Raymond Kurzweil mutatta be. Az adatmennyiség tehát még erősen korlátozott, de az irány nagyon ígéretes: most először lehet természetes nyelven megfogalmazott kérdéseket a könyvekben felhalmozott tudásmennyiségre ráereszteni – ahhoz hasonlóan, ahogy például a Wolfram Alpha faktuális kérdésekre kalibrált okoskeresője is működik, csak ott meghatározott online felületeken keresi a releváns információt.
Ray Kurzweil. (j)
Fotó: TED
A Talk to Books kifejezetten a könyvekben őrzött tudásra megy rá. Egyelőre csak angolul érdemes használni, idővel talán magyarul is lehet majd valamikor használni. A keresés más logika szerint működik, mint azt a sima Google-ben vagy más mkeresőkön megszokhattuk: a mesterséges intelligencia gépi tanulással értelmezi a kérdést, és a bő 100 ezernyi könyv teljes szövegében próbál rá értelmes, releváns válaszokat kihozni. Azt, hogy helyes-e a válasz, hogy az adott könyv referenciamű, netán fikciós szöveg vagy tévedések tárháza, nem vizsgálja. Ennyiben egyáltalán nem biztos, hogy helyes választ kapunk, de részben éppen ettől lesz a dolog szórakoztató.
Példaképpen megnéztem gyorsan, hogy milyen mondatokat talál arra a(z angolul feltett) kérdésre, hogy „miért olyan furcsa a magyar nyelv?” Az első helyeken szereplő találatok:
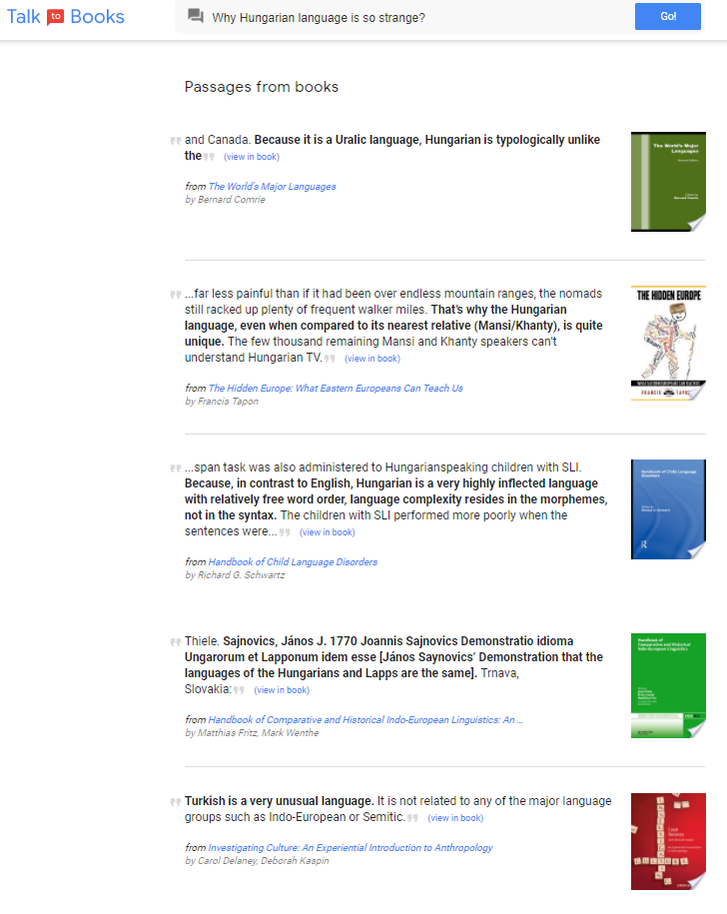
Vagyis:
- mert egy tipológiailag az indoeurópaiaktól eltérő uráli nyelvről van szó;
- még legközelebbi nyelvi rokonaink, a hantik/manysik sem értik a magyar TV-t;
- az angolhoz képest a magyar nyelvben sokféle rag van, viszonylag szabad a szórend és a nyelvi komplexitás a morfémáknak, nem pedig a szintaxisnak köszönhető;
- [Sajnovics János szerint] a magyar és a lapp nyelv ugyanaz.
Az utóbbi persze ma már abszurd állításnak számít, igaz, attól még valóban kapcsolódik a feltett kérdéshez. Az is látszik, hogy becsúszott a többi mellé egy török, egy ujgur és egy gót nyelvre vonatkozó találat is, és általában is sok hasonló, irreleváns találat fordul még elő – ha az adatbázis növekszik, és a gépi tanulás is hatékony, a hibaszázalék folyamatosan csökkenhet majd.
A keresés egyelőre főleg játéknak jó, esetleg felhívhatja a figyelmet néhány könyvre, ami érdekes lehet, kis szerencsével pedig inspirációt, ötleteket, használható idézeteket is találhat benne az, aki ilyesmire vágyik. De a benne lévő potenciál alapján az sem lehetetlen, hogy néhány év múlva ez a mire jó kérdés annyira fog viccesnek tűnni, mint a mire (nem) jó az internet taglalása olyan 25 évvel ezelőtt.
Kövesse az Indexet Facebookon is!
Követem!
