


Mesterséges intelligenciával a veszélyeztetett lovakért
Kövesse az Indexet Facebookon is!
Követem!További Tech-Tudomány cikkek
A Debreceni Egyetem több oldalról is vizsgálja a mesterséges intelligencia hasznosságát. A technológiát használják orvosi adatok elemzésére és egyesítésére, vadlovak vizsgálatára és nyúlgének kutatására is. Az egyetem MI Tudásközpontjának kutatóit a Microsoft támogatja, hogy elmélyedhessenek az MI és a gépi tanulás használatában. Az idei tanévben háromról kilencre nőtt az ilyen kurzusok száma, 19 oktató adja át a felhővel, mesterséges intelligenciával és gépi tanulással kapcsolatos tudást és közel 600 hallgató végezte el a Microsoft Azure technológiára épülő kurzusokat.
Az egyetem minden hallgatója rendelkezik 100 dollárnyi kredittel, amit az Azure felhőalapú szolgáltatásaira költetnek.
Ez például azért hasznos, mert egy kutatáshoz így nem kell venni külön egy erős, drága számítógépet, amit aztán lehet, hogy elő se kell venni többet, hanem gyakorlatilag ki lehet kölcsönözni a kutatáshoz szükséges eszközöket a felhő segítségével. Az Informatikai Kar részt vesz egy gyógyszeripari kutatásban, amihez a felhőn át kölcsönöz a Microsofttól egy megfelelően erős gépet, ami pont illeszkedik a kutatás erőforrás-igényeihez.
Az MI Tudásközpont kutatói kedden egy online sajtótájékoztatón mutattak be két olyan projektet, amiken látható, hogyan segíthetnek ezek a technológiák a mindennapi életben. Az egyik bemutatott kutatás az MI-t és a gépi tanulást használja alföldi vadlovak követésére és vizsgálatára. Dr. Barta Zoltán beszélt a hatodik kihalás hullámról, ami ökoszisztémák összeomlásához vezethet. Az ember azért néha meg is ment egy-egy fajt, Barta erre példának a Przewalski lovakat hozta, amik a '60-as évek végére eltűntek a vadonból, de egy tenyésztési programnak hála ma már több mint 2000-en vannak.

Bár ezek amerikai egyedek, de ilyen lovakat vizsgálnak a Hortobágyon is.
Fotó: The Washington Post / Getty Images Hungary
Minél jobban megismerünk egy fajt, annál könnyebben tudunk segíteni rajtuk, és itt jön képbe az egyetem vadló-kutatása. A Hortobágyi Nemzeti Park egy erre kialakított területén nagyjából 300 ilyen vadló él, de mivel nagyon gyorsan szaporodtak, felmerült a szükség a populációkontrollra. Ehhez általában immunreakció-alapú fogamzásgátlást használnak, amihez pontosan tudni kell, melyik kanca hány kezelésen van túl, ez azonban sok munkát jelent a park dolgozói számára.
Ezzel párhuzamosan indult egy tudományos vizsgálat is, ami a lovak viselkedését kutatta. A vadlovak társadalmi felépítése – hasonlóan az emberekéhez – lépcsőzetes tehát a nagyobb egység több alegységből áll: az egyedek háremekbe, ezek pedig ménesekbe szerveződnek. Ez a modellrendszer akár az emberi társadalom néhány aspektusának megértésében is segíthet.
A kutatás során a ménes és az alegységek mozgásmintázatát követték nyomon és elemezték. Melyik ló dönt az irányról? Van különbség hárem és hárem között, vagy azonos mértékben hatnak a döntéshozásra? Hogyan halad át az információ a ménesen? Ezek megválaszolására drónokat használnak, amikkel követik a lovakat. A felvételeket a kutatók manuálisan elemzik, és kockázzák a lovakat. Az egyedek koordinátái alapján tudnak válaszokat keresni a kérdésekre.
Ez a manuális elemzés (akárcsak a parki projektnél) erőforrás igényes, és itt jön képbe az MI és a gépi tanulás. A korábban készített, nagy felbontású videókon a kutatók már lekódolták, hol vannak a lovak, amivel remekül meg tudták tanítani az MI-nek, hogy ismerje fel az egyedeket. Ehhez az Azure-ral és egy saját szerveren, kisebb skálán kísérleteznek.
Az MI jelenleg több, mint 90 százalékos azonosítási pontosságra képes, és az egyik legnagyobb eredménye az, hogy már könnyen megkülönbözteti a lovakat a környéken élő szarvasmarháktól.
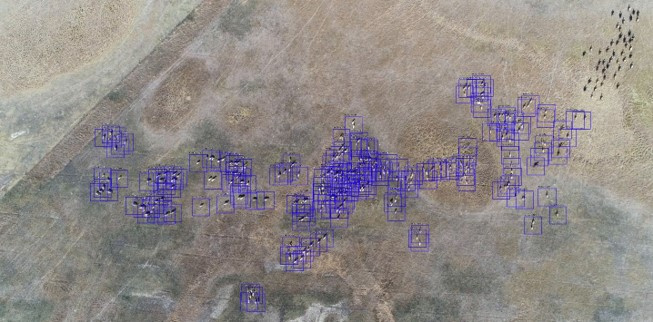
Jól látható, hogy az MI a lovakat felismerte, de a marhákat nem.
Fotó: Debreceni Egyetem
A cél egy olyan algoritmus fejlesztése, ami azonosítani tudja a lovakat egyedi jellegzetességek (például szín, mintázat alapján) alapján. Ezt nem csak a Hortobágyi Nemzeti Park, hanem akár bármilyen más, vadlovakkal foglalkozó intézmény használhatná. Kérdésünkre Barta azt mondta, hogy nem nulláról indultak, nem egy teljesen tudatlan mesterséges intelligenciával kezdtek, és az általuk készített algoritmusokat néhány paraméter-igazítással más állatok vizsgálatára is fel lehet használni.
Akár 40-szer gyorsabb a felhőben
Egy másik projektről Dr. Emri Miklós, az egyetem tudományos főmunkatársa beszélt. Az MI Tudásközpont fejlesztői egy olyan adatbázist hoztak létre, amiben 1,3 millió anonim beteg adatait gyűjtötték össze, és amiben ezeknek az adatoknak (például laboreredmények, kórtörténet és CT felvételek) az automatikus feldolgozása, elemzése és rendszerezése zajlik. Az Azure felhőalapú szolgáltatásának segítségével a kutatók akár egy laptop böngészőjéből is hozzáférnek ehhez az adatbázishoz, és kihasználhatják az elemző eszközöket, ehhez nincs szükség bivalyerős számítógépekre az egyetemen.
Az adatok begyűjtése és rendszerezése mellett több adattisztítási projektet is elindítottak. Ezeknek az egyik célja a sztenderdizálás, amivel az adatokat olyan formába írják át, ami segítségével statisztikai mérésekben is felhasználhatóvá válnak – ehhez a sztenderdizáláshoz is használnak gépi tanulást.
Ez veszélyesnek hangozhat, de a fejlesztők több biztonsági intézkedést is beépítettek a rendszerbe. Először is, ha valaki használni szeretné, le kell adnia egy etikai kérvényt. Ha ez megvan, akkor el kell végeznie egy Azure-os képzést, hogy megismerje a rendszer eszközeit.Ezek után kaphat jogosultságot a rendszerhez, azaz egy mobil alkalmazást és ahhoz egy jelszót, hogy a banki rendszerekhez hasonlóan két lépcsős azonosítással igazolja, hogy valóban ő akar belépni.
A projekthez két felhőt is használnak. Az elsőben a rendszer található, a második felhővel pedig egy olyan összeköttetést építettek ki, ami dinamikusan csökkenti a használt számítógépek számát annak függvényében, hogy hányan és milyen intenzitással használják a rendszert.
Hogy teszteljék az Azure adottságait, lefoglaltak 200 darab 16 magos számítógépet, és egy 1TB-nyi adatot töltöttek fel. A számolás 1 (egy) napig tartott, minden előkészülettel együtt egy hétig. Az egyetem szerverein ugyanez 30-40 napot vett volna igénybe.
Megkérdeztük, hogy mennyire biztonságos egy ilyen adatbázis a páciensek személyes adatai szempontjából. Emri azt mondta, hogy nincs esélye annak, hogy a betegek személyiségi jogai csorbuljanak, hiszen bárhol kezelik az adatokat, teljesen anonim módon teszik. A jelenlegi rendszer még csak tesztadatokat használ, de már a projekt elindulásához is illeszkednie kellett a terveknek az egyetem GDPR-szabályzatához.
Kövesse az Indexet Facebookon is!
Követem!
