

Hallucinálnak a webfordítók
Kövesse az Indexet Facebookon is!
Követem!További Tech cikkek
-
 Olyat hibát produkál a Windows, hogy garantáltan mindenki kiugrik a székéből
Olyat hibát produkál a Windows, hogy garantáltan mindenki kiugrik a székéből - Könnyen megeshet, hogy a Google kénytelen lesz eladni a Chrome-ot
- A Huawei hivatalosan is bejelentette, előrendelhető a Mate 70
- Lesöpörheti Elon Musk X-ét a Bluesky, már a Google is relevánsabbnak találja
- Ezek a leggyakrabban használt jelszavak – érdemes változtatni, ha ön is használja valamelyiket
A Microsoft magyar nyelvű fordítójának megjelenése után közröhej tárgya lett, hogy Békéscsabát Chicagónak fordította. Utánajártunk, hogyan működnek a webes fordítók, és miért lett Mogyoródból Mexico City, Veszprémből Las Vegas. Egy év múlva talán jobb lesz a helyzet, Magyarországon indul az az összeurópai projekt, amelyik a mostaninál pontosabb fordításokat ígér.
Szövegek gépi fordítására rengeteg program létezik már, a legismertebbek ezek közül persze a netes webfordítók. A Google Translate tavaly február óra fordít magyarra, a Microsoft keresőjére épülő fordító március eleje óta. Közben Magyarországon már 2006 óta létezik a Morphologic webes fordítója, a webforditas.hu. Ezek a rendszerek sokat segíthetnek, ha egy teljesen ismeretlen nyelven írott szöveget akarunk nagyjából megérteni, de sokszor – különösen hosszabb mondatoknál – pontatlanok. Tihanyi Lászlóval, a Morphologic egyik alapítójával beszélgettünk a webes fordítók titkairól.
Nyelvészeti rendszerek
A fordítóprogramoknál két főbb rendszert különböztetünk meg. Az egyik az úgynevezett szabályalapú rendszerek csoportja, itt nyelvtani szabályok alapján közelítik meg a problémát, ilyet használ a Morphologic is. Ezek a rendszerek az úgynevezett generatív grammatikán alapulnak. E szerint egy nyelv az alkotóelemeinek szótárból és véges számú olyan szabályból áll, amelyekkel a nyelvtanilag helyes mondatok létrehozhatók. Ha ismerjük egy nyelv elemeit és transzformációs szabályait, akkor meghatározhatjuk az adott nyelven helyes mondatok szerkezetét. Ez a mondatstruktúra általában egy fa alakú ábrában reprezentálható.
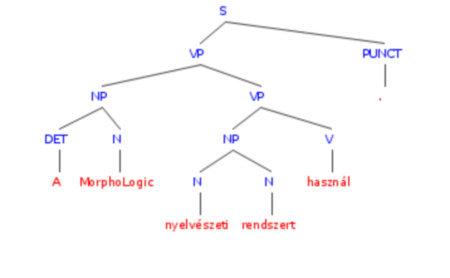
Az ilyen fordítóprogram megpróbálja feltárni a fordítandó szöveg mondatainak struktúráját, ágrajzát. Először azokat a szomszédos elemeket (szavakat) próbálja összefogni, amelyek valószínűleg nyelvtanilag is együvé tartoznak. Az elemzés megtalálja az igét, a főneveket, a határozószókat. Ehhez a programnak szóelemzést is kell végeznie, azaz a program szóelemző része felismeri a szavak tövét és toldalékait (azaz szószerkezettanilag – morfológiailag – elemzi a szavakat, és felismeri, hogy a kutyáknak szóban a kutya a szótő).
A program ezután megpróbál magasabb rendű szerkezeteket felismerni, megtalálni az olyan nyelvtani egységeket, mondatösszetevőket, mint például azok, amiket alanynak vagy állítmánynak neveznek. A program jó esetben az összes elemet (a mondatban levő valamennyi szót és alkotóelemeiket) azonosítja, és létre tudja hozni a mondat a teljes faszerkezetét, és azt is felismeri, hogy az elemekből milyen szabályok hozták létre az adott szerkezetet. Ha a program a lefordítandó mondatról össze tud állítani egy ilyen fát, és ha a kielemzett mondattani – szintaktikai – szerkezet azonos a mondat valódi szerkezetével, a fordítás szinte tökéletes lesz.
Két probléma lehet. Ha egynél több ilyen elemzés lehetséges, akkor a mondat többértelmű. Ez a ritkább eset, ilyenkor választani kell a lehetőségek közül. A fordítás nyelvileg mindig helyes lesz, de lehet, hogy az értelme nem felel meg a kontextusnak.
A másik eset, amikor egyetlen teljes elemzés sincs, a program nem tudja megrajzolni a fát, nem ismeri föl a mondatot létrehozó szabályokat. Márpedig ma még nagyon sok mondatot nem tudunk maradéktalanul elemezni. Ennek két oka lehet: a még mindig hiányos nyelvi leírás vagy a hibás fordítandó szöveg. Ha a program nem ért valamit, akkor a mondat darabjait egymástól függetlenül fordítja le. Ezek a széttöredezett szerkezetek adják a sokszor hibás vagy érthetetlen fordításokat.
Hogyan lesz ebből angol mondat?
Minden kielemzett szabályhoz rendelhető egy generáló szabály, például egy magyarhoz egy angol. Fordításkor a program megnézi, hogy az adott mondatot elemzése szerint milyen szabályok hozták létre a magyarban, és a fordított irányban haladva a megfelelő angol szabályokkal fölépíti a mondatszerkezetet, és a generált fa levelein lévő szavak összeolvasásával előáll a fordítás. A Morphologic webes fordítója ezen az elven működik.
Statisztikus rendszerek
A másik csoportot a statisztikus rendszerek alkotják. Ilyet használ például a Google és a Bing is. Ezek a programok nem határozzák meg a lefordítandó mondatok szerkezetét, a fordítás meglévő szövegekből áll elő. Két adatbázissal dolgoznak. Az egyikben szövegpárok vannak, vagyis egy szöveggyűjtemény az egyik nyelven és annak fordítása a másik nyelven. A másik adatbázis a célnyelven írt szövegek nagy gyűjteménye.
Nézzük először a kétnyelvű adatbázist. Amikor beírunk egy mondatot, a fordítóprogram megvizsgálja, hogy a mondat szavaihoz, illetve többszavas szerkezeteihez milyen valószínűséggel talál célnyelvi megfelelőt. Ezek a rendszerek a nyelvről nem tudnak semmit, fontos különbség, hogy csak az egyforma szavakat ismerik fel, tehát a kutyának szóban nem ismerik fel a kutya szót. Miután a program megtalálja az adott szót a frázistáblában, megnézi a szóhoz tartozó valószínűséget. Például a dog mellett a kutya valószínűsége 0,8 lesz (azaz az adatbázisban levő fordítások 80%-ában a dog szót a kutya szóval fordították le), az eb-é 0,1, a macska szóé ennél is kisebb.
A folyamatban nemcsak szavak, hanem szópárok, hosszabb szósorozatok lehetséges jelentéseit is felhasználják. Megvizsgálják két egymás mellett lévő szó együttes előfordulásának a valószínűségét, aztán háromét, és tovább. Az titok, hogy például a Google vagy a Bing milyen hosszúságú elemek valószínűségét tárolja. Minden, a weben előforduló teljes mondat eltárolása meghaladja a számítógépes kapacitást, ezért az adatbázis készítésénél, illetve a fordításkor is darabokra tördelik a mondatokat.
Miután létrejött a lehetséges fordítások listája, jöhet a második adatbázis, a célnyelvi korpusz. Megintcsak statisztikai alapon megpróbálják kitalálni, hogy mely fordítások illenek leginkább egy célnyelvi mondatba, és hogyan kell összerakni a szavakat, szósorozatokat úgy, hogy az egész mondat valószínűsége a lehető legnagyobb legyen.
Vicces félrefordítások, hallucináció
A Bing megjelenése után sokan hüledeztek azon, hogy lehet Veszprém-et Las Vegas-nak fordítani, és hogy lehet, hogy az Isten, áldd meg a magyart fordítása God bless the United States. A magyarázat a hallucináció.
Az ok a statisztikában van. Tegyük fel, hogy az Isten, áldd meg és a God bless the páros valószínűsége olyan nagy, hogy a program ezt választja fordításul. Habár a magyar szó legvalószínűbb jelentése a Hungarian, de gyakran szerepel olyan mondatokban, amelyekben a megfelelő angol mondatban ugyanitt az English vagy a United States áll, ezért a rendszer ezeket is lehetséges fordításnak tekinti.
Ezután kezdődik a kirakós, a legvalószínűbb angol mondat keresése. Mivel a God bless the szósorozatot a tanulóanyagban leggyakrabban a United States követte, és mivel a magyar szónak volt ilyen fordítása is, ezért az eredő valószínűség ennél lesz a legnagyobb, így a program ezt választja lehetséges fordításul.
És hogyan lesz Veszprém-ből Las Vegas? Itt egy másik probléma lép fel, hiszen a Veszprém szót a Microsoft önmagában, környezet nélkül is Las Vegas-ra fordítja. Ez az elégtelen méretű tanulószöveg miatt jöhet létre. Feltételezhető, hogy a Veszprém szó a tanítókorpuszban csak nagyon kevésszer fordul elő, és ezért a program nem tudta a megfelelő fordítást hozzárendelni, valamilyen zaj vált meghatározóvá.
És itt el is érkeztünk a statisztikus programok lényegéhez, ugyanis minél nagyobb adatbázisban tudnak keresni a programok, annál nagyobb a valószínűsége, hogy megtalálják a helyes fordítást. Kicsi adatbázisoknál még az is előfordulhat, hogy a Szolnok fordítása navigated to lesz.
A jövő
A jövő a szintézisé, már meg is jelentek az első hibrid fordítók. Ilyen a híres Babelfish oldal mögött álló Systran is. Ez a legrégebbi és legtöbbek által használt (mellesleg a magyar származású Toma Péter által létrehozott) szabályalapú fordítóprogram tavaly októberben jelent meg egy olyan változattal, amelyik a célnyelvi mondatok összeállításában figyelembe veszi azok statisztikai valószínűségét, érezhetően javult is a fordítások minősée.
A közeljövőben várható, hogy a szabályalapú rendszerek statisztikai modullal egészülnek ki, hiszen ez pusztán nyílt forráskodú programok integrációját jelenti. Ugyanakkor a helyzet aszimmetrikus, a statisztikai rendszerek nem férhetnek hozzá a féltve őrzött, költséges munkával kidolgozott nyelvészeti adatbázisokhoz, szótárakhoz.
További probléma, hogy ma mindhárom magyar webfordító (webforditas, Google, Microsoft) az angolon nyelv közvetítésével fordít más nyelvekre, illetve nyelvekről. Tehát amikor magyarról olaszra fordítunk, a programok a szöveget először angolra fordítják, majd angolról olaszra. Ez persze megnöveli a hibák számát is.
Van azonban egy uniós projekt, amely még erre a problémára is választ kíván adni. Egyetlen webhelyen szeretnék elérhetővé tenni az összes fordítóprogramot. A projekt élén az MTA Nyelvtudományi Intézete áll, a technikai hátteret a MorphoLogic adja. A magyar ötlet nyomán az Európai Unió megbízást adott egy olyan oldal létrehozására, amelyen ingyen lehet bármelyik nyelvről bármelyik nyelvre fordítani, sőt sokszor egyedül álló módon, több fordító megoldása közül is válogathatunk. Az összeurópai projektbe meghívást kapott minden olyan európai fordítócég, amelyik a legjobb fordítást szolgáltatta valamelyik európai nyelv és az angol között.
A tíztagú üzemeltető konzorcium egy év múlva indítja el a szolgáltatást. A készülő honlapon ráadásul megjelennek olyan nyelvpárok is, amelyeket nem az angolon keresztül fordítanak majd, például lesz közvetlen német–francia fordító is. A rokon nyelveknél a nyelvcsaládon belüli nyelv lesz a közvetítő, például bolgár és szlovák között az orosz.
Kövesse az Indexet Facebookon is!
Követem!
